This paper addresses the scarcity of large-scale
datasets for accurate object-in-hand pose estimation, which is crucial for robotic in-hand manipulation within the “Perception-Planning-Control”
paradigm. Specifically, we introduce VinT-6D,
the first extensive multi-modal dataset integrating vision, touch, and proprioception, to enhance
robotic manipulation. VinT-6D comprises 2 milion VinT-Sim and 0.1 million VinT-Real entries,
collected via simulations in Mujoco and Blender
and a custom-designed real-world platform. This
dataset is tailored for robotic hands, offering models with whole-hand tactile perception and high-quality, well-aligned data. To the best of our
knowledge, the VinT-Real is the largest considering the collection difficulties in the real-world environment so it can bridge the gap of simulation to
real compared to the previous works. Built upon
VinT-6D, we present a benchmark method that
shows significant improvements in performance
by fusing multi-modal information. The release
of the VinT-6D dataset and benchmark code will
soon provide a valuable resource for research and
development in robotic manipulation.
VinT-Sim Pipeline
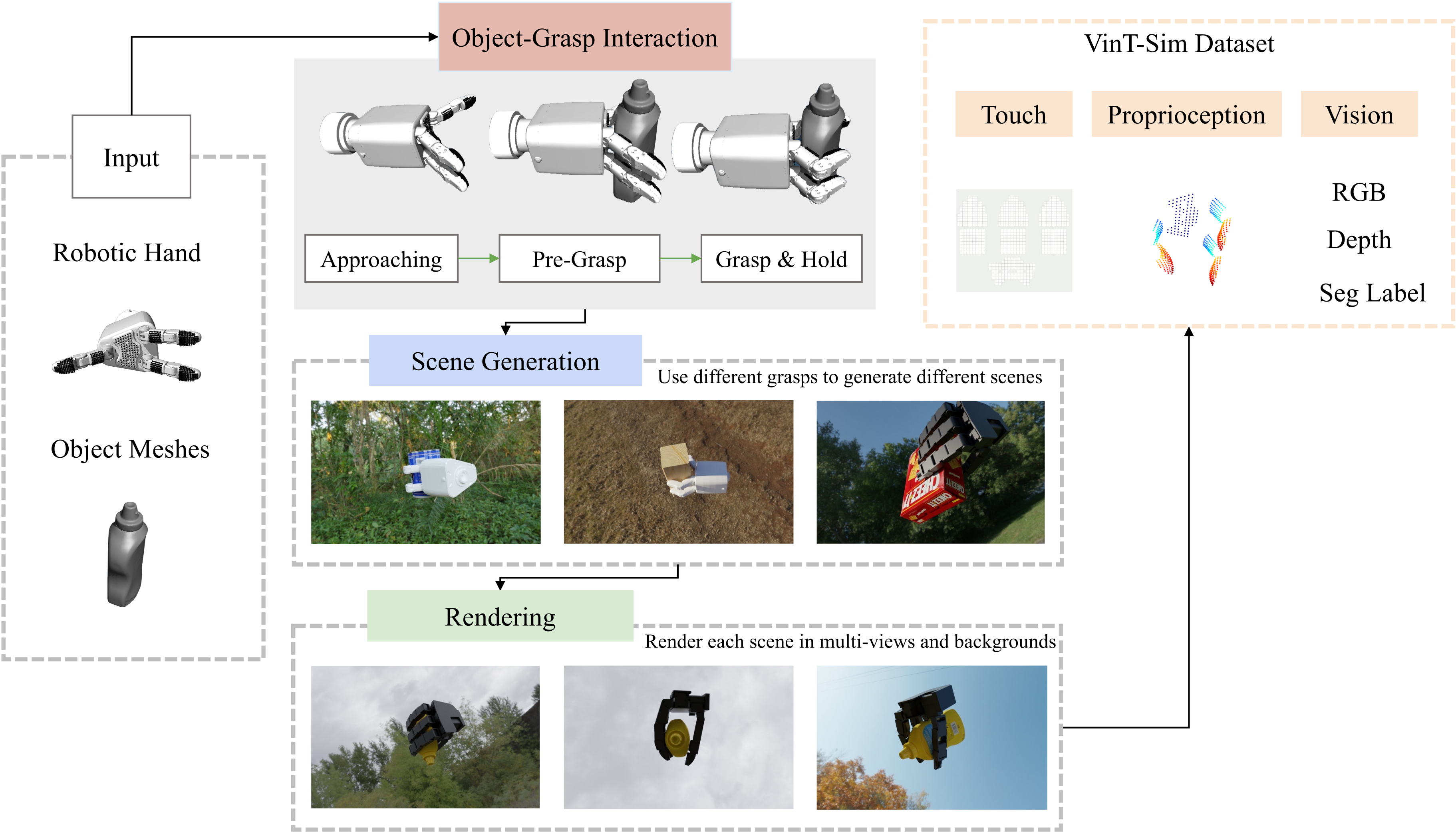
VinT-Sim requires a robotic hand as input, which can have either three or four
fingers along with an object model. There are three components
involved in this process: (1) Object-grasp interaction is used to
generate tactile data and proprioception information. (2) Use different grasps to generate different grasp scenes. (3) Each scene is
rendered with different realistic backgrounds and sampled from
multiple views.
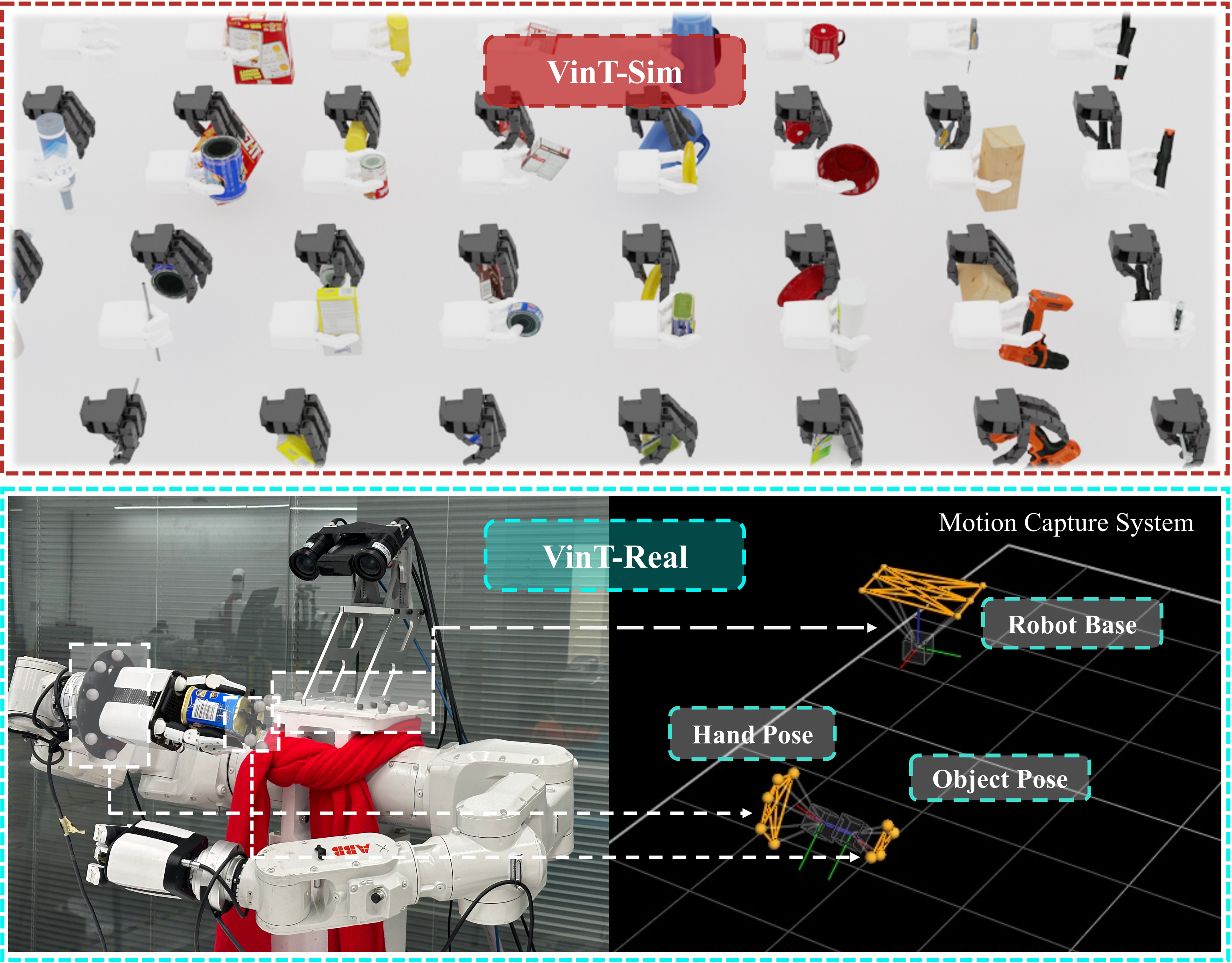
VinT-Real Collection

VinT-Real : Data collection mirroring toddler-like exploration.
VinT-Net Framework
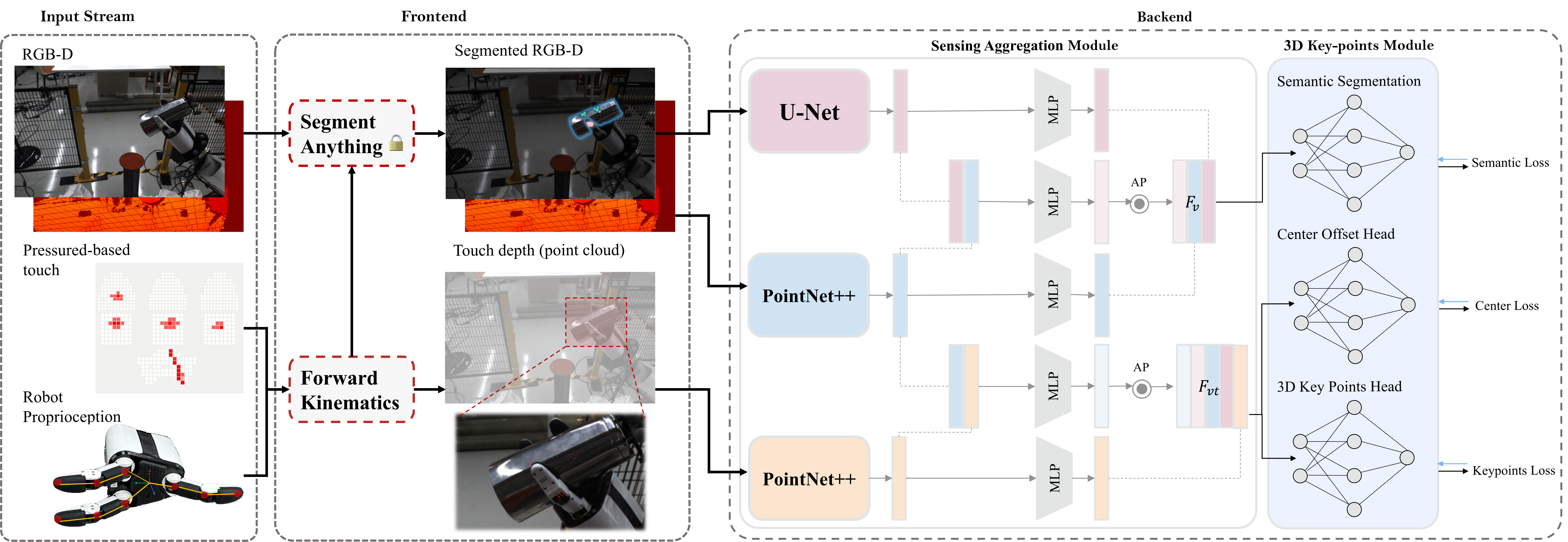
We introduce VinT-Net to enhance research in robotic object-
in-hand pose estimation and set up standard benchmarks.
This network acts as a simple yet effective baseline for multi-
finger object-in-hand pose estimation challenges. VinT-
Net can efficiently process various inputs, such as RGB
and depth images with segmentation labels and local touch
points derived from robotic tactile and proprioceptive sen-
sors. The architecture of VinT-Net comprises two crucial
sub-modules: a sensing aggregation module and a 3D keypoint-based pose estimation module. The framework of VinT-Net is illustrated
in Figure 8. It accurately estimates the object’s 6D pose
from the robot’s camera perspective
BibTeX
@InProceedings{vint6d,
author = {Zhaoliang Wan and Yonggen Ling and Senlin Yi and Lu Qi and Minglei Lu and Wangwei Lee and Sicheng Yang and Xiao Teng and Peng Lu and Xu Yang and Ming-Hsuan Yang and Hui Cheng},
title = {VinT-6D: A Large-Scale Object-in-hand Dataset from Vision, Touch and Proprioception},
booktitle = {Forty-First International Conference on Machine Learning},
year = {2024},
}
![[Poster]](https://icml.cc/media/PosterPDFs/ICML%202024/35027.png?t=1718874161.8117378){kind=link}